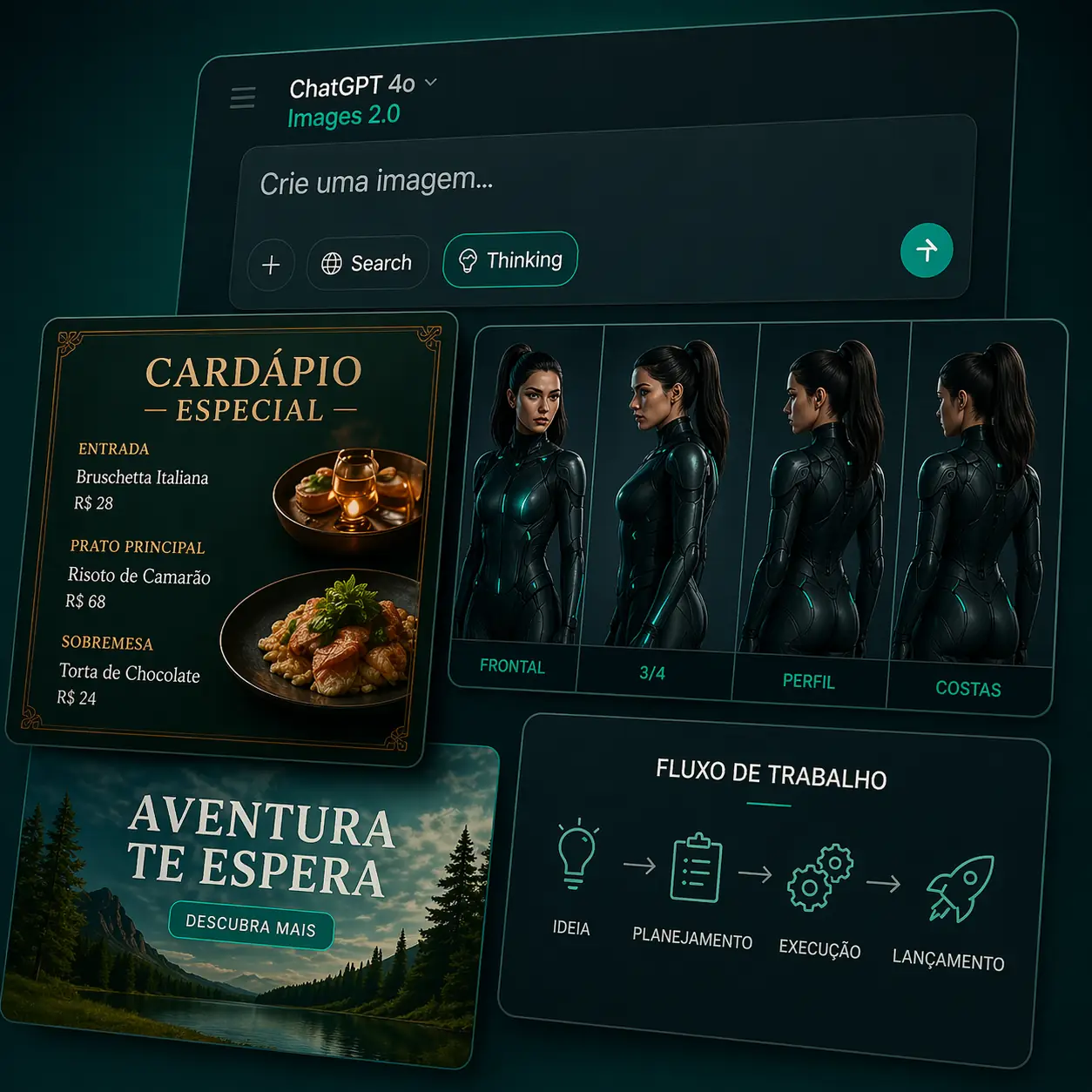
Testei o ChatGPT Images 2.0 no dia do lançamento. O que aconteceu depois me surpreendeu
Quando a OpenAI lançou o Images 2.0 em 21 de abril de 2026, eu estava acordado cedo, já com o ChatGPT aberto.
Fiz alguns testes, tirei prints e joguei nos stories sem pensar muito. Algumas pessoas pediram mais detalhes, queriam entender melhor o que tinha mudado na prática.
Decidi escrever o post porque a pergunta que mais apareceu foi a mais simples: “mas vale a pena de verdade?” E essa pergunta merece uma resposta honesta, não um hype.
Não é um guia técnico. É o que eu, como designer que ganha a vida gerando materiais visuais para clientes, encontrei de relevante nessa atualização, e o que ainda acho que falta.
—
O que é o ChatGPT Images 2.0
Lançado em 21 de abril de 2026 pela OpenAI, o Images 2.0 é o primeiro modelo de geração de imagem da empresa com capacidades nativas de raciocínio visual. Isso muda a lógica de como a ferramenta funciona.
Ele substituiu o DALL-E 3 e o GPT Image 1.5, que serão desativados em 12 de maio de 2026. Está disponível direto no ChatGPT, no Codex, e via API para quem desenvolve produtos.
Mas o que significa “raciocínio nativo” na prática? Significa que antes de gerar qualquer pixel, o modelo planeja. Ele verifica composição, conta objetos, checa relações espaciais. Não tenta gerar na força bruta e corrigir depois.
—
O que realmente mudou: 5 viradas práticas
Não vou listar especificações de paper. Vou traduzir o que importa para quem usa isso no trabalho.
1. Texto dentro da imagem finalmente funciona
Essa era a limitação mais frustrante de qualquer modelo de imagem nos últimos anos. Você pedia um cardápio, um banner com preço, um infográfico com dados, e a ferramenta produzia um visual bonito com texto completamente ilegível ou inventado.
O Images 2.0 resolveu isso. Pedi um banner com o valor “R$ 2.997” em destaque, fonte bold, fundo escuro, e ele acertou na primeira tentativa. Sem erros ortográficos, sem número trocado. Parece pouca coisa até você lembrar quantas horas foram perdidas corrigindo texto em Photoshop depois de gerar uma base no DALL-E.
2. O modelo pensa antes de gerar
Antes de produzir a imagem, o sistema faz um processo interno de planejamento: analisa a composição, verifica se o número de objetos pedidos está correto, checa alinhamento espacial. Isso reduz dramaticamente o número de tentativas necessárias para chegar em algo utilizável.
Na prática: antes eu precisava gerar 8, 10 variações para achar uma que tivesse todos os elementos no lugar. Agora chego em 2 ou 3.
3. Até 8 imagens consistentes em um único prompt
Esse ponto abre caminho para um trabalho que antes era inviável sem ferramentas específicas: gerar um personagem consistente em múltiplas cenas. Mesmo rosto, mesma paleta, mesmo estilo gráfico, em todas as 8 imagens do lote.
Para quem cria pôsteres, storyboards, carrosséis com personagem ou qualquer sequência visual, isso é uma mudança de nível.
4. Proporções reais de trabalho
O modelo aceita proporções de 3:1 a 1:3. Isso cobre banners horizontais, posts verticais para mobile, slides de apresentação, pôsteres. Antes a limitação de proporção obrigava a retrabalho de crop depois da geração. Agora você especifica o formato e o modelo já compõe para ele.
5. Busca na web durante a geração
No modo Thinking, o modelo pode consultar referências externas e dados reais enquanto gera. Isso ajuda especialmente em infográficos com dados atuais e mapas com nomes corretos de lugares, casos onde um modelo sem essa capacidade simplesmente inventava informação.
—
Quem tem acesso e como funciona
O Images 2.0 tem dois modos:
O modo Instant está disponível para todos os usuários, incluindo o plano gratuito. Mais rápido, sem busca na web, sem lote de 8 imagens.
O modo Thinking, que inclui busca web, geração em lote de até 8 imagens e verificação estendida de composição, é exclusivo dos planos Plus, Pro, Business e Enterprise.
Um dado curioso: o Brasil é o país com maior adoção proporcional do recurso no mundo, segundo os números que circularam nos dias seguintes ao lançamento. Não surpreende. Aqui a galera adota ferramenta nova mais rápido que em qualquer outro lugar.
—
Casos de uso práticos para quem trabalha com criação
O óbvio primeiro: posts para Instagram, banners para tráfego pago, mockups de site para apresentar ao cliente. Mas o que me interessa mais são os casos menos óbvios.
Thumbnails para YouTube com texto funcional. Carrosséis com personagem consistente em todos os slides. Infográficos com dados reais sem precisar abrir o Illustrator para corrigir cada número. Layouts editoriais para proposta de identidade visual. Protótipos de interface para validar conceito antes de ir pro Figma. Storyboards para briefing de vídeo.
—
Minha experiência real
No dia do lançamento, fiz quatro testes seguidos.
O primeiro foi o mais simples: um banner para um mentor de negócios com preço em destaque. Prompt: “crie um banner para mentor de negócios, fundo escuro grafite, texto em branco, valor R$ 2.997 em destaque na parte inferior direita, composição limpa, tipografia bold, sem elementos decorativos”. O resultado saiu na primeira geração, texto correto, sem erro.

O segundo teste foi com texto em português: um cardápio de cafeteria com cinco itens, preços e descrições curtas. Antes era garantia de frustração em qualquer modelo. Aqui funcionou com ajustes mínimos no segundo prompt.

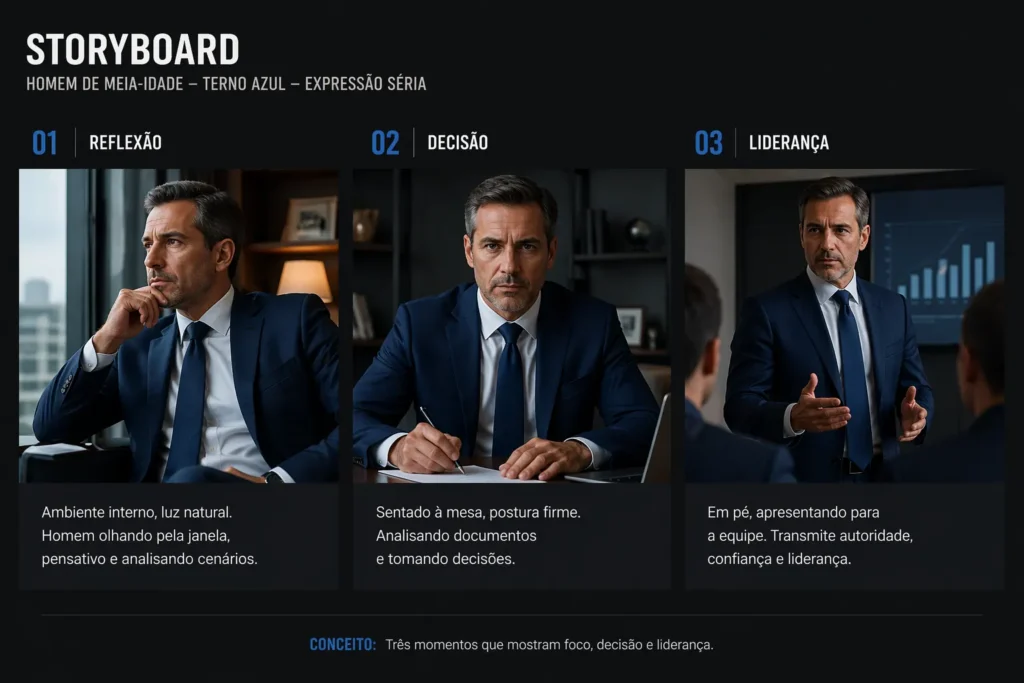
O terceiro: storyboard de três cenas com o mesmo personagem. Pedi um homem de meia-idade, terno azul, expressão séria, em três situações diferentes. O modo Thinking manteve a aparência e a paleta nas três cenas. Não perfeito, mas consistente o suficiente para usar como referência de briefing para cliente.
—
Limitações honestas
Todo review que ignora os pontos negativos está tentando te vender algo. Então:
O conhecimento do modelo vai até dezembro de 2025. Se você pedir algo que depende de eventos recentes, figuras públicas de 2026 ou dados novos, o resultado pode ser impreciso ou inventado. Para prompts que dependem de atualidade, o modo Thinking com busca na web ajuda, mas não resolve tudo.
O modo Thinking é mais lento. Para composições complexas, espere entre 15 e 30 segundos por geração. Se você precisa de volume rápido, o modo Instant é mais adequado.
A arquitetura exata do modelo não foi divulgada pela OpenAI. Não sabemos os detalhes técnicos de como o raciocínio funciona internamente. Isso não afeta o uso prático, mas é honesto deixar claro.
—
O agente gratuito que criei para facilitar
Depois dos testes, percebi que a curva de aprendizado maior não é a ferramenta em si, é saber construir o prompt certo para o Images 2.0 entregar o que você precisa.
Então criei o Creative Engine, um agente gratuito com três camadas de inteligência trabalhando em sequência para quem produz materiais visuais no dia a dia.
Funciona assim: você entra com um briefing simples, uma frase do tipo “quero um banner para anunciar minha mentoria” ou “preciso de um criativo para clínica de estética que gere agendamentos”. O agente divide o trabalho em três etapas automáticas:
- Agente estratégico: define a ideia central, o público, o ângulo e o objetivo da peça antes de qualquer coisa
- Agente estrutural: monta a arquitetura do conteúdo, seja um carrossel de stories, uma arte estática ou um feed, com headline, subheadline e CTA posicionados para converter
- Agente visual: entrega o layout, a paleta, a tipografia, os elementos visuais e o prompt de imagem otimizado para o Images 2.0, pronto para executar
O resultado sai estruturado e pronto para usar no Canva, no Figma ou direto no ChatGPT Images. Sem ficar tentando adivinhar o prompt certo no escuro.
O exemplo abaixo saiu de um briefing de 10 palavras: “arte para clínica de estética, clean, que converta agendamentos”.


Texto correto, composição pronta, CTA no lugar certo. Primeira geração.
Disponibilizei gratuito. Se você usa e funciona, volta. Se compartilha com alguém, melhor ainda.
Acessar o Creative Engine gratuitamente
—
Como gerar resultados melhores no Images 2.0
Especifique o formato antes de descrever o visual. Comece o prompt com a proporção e o destino: “banner horizontal 3:1 para tráfego pago no Instagram”, depois descreva o visual. O modelo compõe para o formato certo desde o início.
Diga o que não quer. O modelo responde bem a instruções negativas. “sem elementos decorativos”, “sem gradientes”, “sem mais de dois elementos no frame” reduzem variações desnecessárias e chegam mais rápido no que você precisa.
No modo Thinking, peça verificação explícita. Adicione no final do prompt: “verifique se todos os textos estão corretos antes de gerar”. Isso ativa o processo de revisão interno e reduz erros tipográficos, especialmente em prompts com números e preços.
Para consistência de personagem, descreva no início e use o lote de 8. Em vez de gerar uma imagem e tentar replicar, descreva o personagem com precisão logo no primeiro prompt e peça as 8 variações de uma vez. O modelo mantém consistência muito melhor dentro do mesmo lote do que entre gerações separadas.
—
Fechamento
O ChatGPT Images 2.0 não é uma atualização cosmética. O texto funcional e o raciocínio antes de gerar mudam o fluxo de trabalho de forma concreta para quem produz materiais visuais no dia a dia.
Não acho que substitui o Figma, o Photoshop ou o julgamento de um designer experiente. Acho que elimina horas de retrabalho em tarefas específicas: gerar uma primeira versão utilizável, testar composições rapidamente, produzir material com texto correto sem depender de pós-edição.
Para quem trabalha sozinho ou em equipe pequena, isso importa muito.
Se você testou e teve uma experiência diferente da minha, quero saber. Me manda no Instagram. E se achou o post útil, compartilha com alguém que ainda não sabe que isso existe.



